隨著互聯(lián)網(wǎng)的蓬勃發(fā)展,數(shù)據(jù)已成為驅(qū)動(dòng)企業(yè)決策與創(chuàng)新的核心生產(chǎn)要素。大數(shù)據(jù)系統(tǒng)作為處理海量信息的基石,其效能高度依賴于前端數(shù)據(jù)采集環(huán)節(jié)的質(zhì)量與效率。本文旨在深入剖析大數(shù)據(jù)系統(tǒng)中數(shù)據(jù)采集產(chǎn)品的典型架構(gòu),并探討其在互聯(lián)網(wǎng)數(shù)據(jù)服務(wù)中的關(guān)鍵作用與演進(jìn)趨勢。
一、大數(shù)據(jù)采集產(chǎn)品的核心架構(gòu)層次
一個(gè)成熟的大數(shù)據(jù)采集產(chǎn)品通常采用分層、模塊化的設(shè)計(jì)思想,其架構(gòu)可概括為以下幾個(gè)核心層次:
- 數(shù)據(jù)源適配層:這是架構(gòu)的入口,負(fù)責(zé)與紛繁復(fù)雜的異構(gòu)數(shù)據(jù)源對接。它需要提供豐富的連接器(Connector)或插件(Plugin),以支持從關(guān)系型數(shù)據(jù)庫(如MySQL、Oracle)、NoSQL數(shù)據(jù)庫(如MongoDB、Redis)、日志文件(如Nginx、應(yīng)用日志)、消息隊(duì)列(如Kafka、RocketMQ)、API接口以及各類傳感器和物聯(lián)網(wǎng)設(shè)備中實(shí)時(shí)或批量地抽取數(shù)據(jù)。該層的設(shè)計(jì)關(guān)鍵在于協(xié)議的兼容性、數(shù)據(jù)格式的解析能力以及連接管理的健壯性。
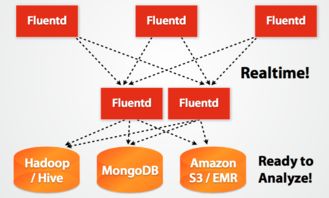
- 數(shù)據(jù)采集引擎層:這是架構(gòu)的“心臟”,負(fù)責(zé)執(zhí)行核心的數(shù)據(jù)拉取(Pull)或接收(推送,Push)邏輯。引擎需具備高吞吐、低延遲的特性,并支持多種采集模式:
- 批量采集:按固定周期(如每小時(shí)、每天)全量或增量同步數(shù)據(jù),適用于對實(shí)時(shí)性要求不高的場景。
- 實(shí)時(shí)/流式采集:通過監(jiān)聽數(shù)據(jù)庫變更日志(如CDC)、或持續(xù)消費(fèi)消息隊(duì)列,實(shí)現(xiàn)毫秒級的數(shù)據(jù)捕獲,滿足實(shí)時(shí)監(jiān)控、風(fēng)控等場景需求。
* 事件驅(qū)動(dòng)采集:響應(yīng)特定事件或條件觸發(fā)采集任務(wù),靈活度高。
引擎還需集成任務(wù)調(diào)度、負(fù)載均衡、故障轉(zhuǎn)移與斷點(diǎn)續(xù)傳等關(guān)鍵能力,確保采集過程的穩(wěn)定與可靠。
- 數(shù)據(jù)處理與緩沖層:原始數(shù)據(jù)往往格式不一且包含雜質(zhì)。此層負(fù)責(zé)進(jìn)行輕量級的即時(shí)處理,如數(shù)據(jù)格式標(biāo)準(zhǔn)化(JSON、Avro等)、字段過濾、脫敏清洗、簡單轉(zhuǎn)換等。處理后的數(shù)據(jù)通常被寫入一個(gè)高性能的緩沖隊(duì)列(如Kafka、Pulsar),起到解耦采集與后續(xù)計(jì)算、平滑流量峰谷、保障數(shù)據(jù)不丟失的關(guān)鍵作用。
- 元數(shù)據(jù)與管理層:這是架構(gòu)的“大腦”,為整個(gè)系統(tǒng)提供可觀測性與可控性。它包括:
- 任務(wù)管理與監(jiān)控:提供可視化界面以配置、啟動(dòng)、停止采集任務(wù),并監(jiān)控其運(yùn)行狀態(tài)、吞吐量、延遲等核心指標(biāo)。
- 元數(shù)據(jù)管理:記錄數(shù)據(jù)源結(jié)構(gòu)、數(shù)據(jù)流向、血緣關(guān)系等信息,便于數(shù)據(jù)治理與溯源。
- 配置中心與權(quán)限管理:集中管理連接參數(shù)、處理規(guī)則,并控制不同用戶對數(shù)據(jù)源和任務(wù)的訪問權(quán)限。
- 目標(biāo)輸出層:負(fù)責(zé)將經(jīng)過緩沖和處理的數(shù)據(jù),可靠地寫入下游的各類數(shù)據(jù)存儲(chǔ)或計(jì)算系統(tǒng),如數(shù)據(jù)湖(HDFS、S3)、數(shù)據(jù)倉庫(Hive、ClickHouse)、實(shí)時(shí)計(jì)算平臺(tái)(Flink、Spark Streaming)或搜索分析引擎(Elasticsearch)等。
二、架構(gòu)設(shè)計(jì)的關(guān)鍵技術(shù)考量
- 可擴(kuò)展性與彈性:采用分布式、微服務(wù)化設(shè)計(jì),支持水平擴(kuò)展以應(yīng)對數(shù)據(jù)量增長。在云原生環(huán)境下,能夠利用Kubernetes等容器編排技術(shù)實(shí)現(xiàn)彈性伸縮。
- 可靠性保障:通過事務(wù)機(jī)制、WAL(Write-Ahead Logging)日志、多副本存儲(chǔ)以及完善的錯(cuò)誤重試與告警機(jī)制,確保數(shù)據(jù)在端到端傳輸過程中的“Exactly-Once”或“At-Least-Once”語義。
- 性能優(yōu)化:采用異步I/O、多線程/協(xié)程、批量提交、數(shù)據(jù)壓縮等技術(shù)最大化吞吐,降低資源消耗。
- 生態(tài)兼容性:積極融入主流大數(shù)據(jù)生態(tài)系統(tǒng)(如Apache系列項(xiàng)目),提供標(biāo)準(zhǔn)化的接口,降低集成成本。
三、互聯(lián)網(wǎng)數(shù)據(jù)服務(wù)中的實(shí)踐與演進(jìn)
在互聯(lián)網(wǎng)數(shù)據(jù)服務(wù)領(lǐng)域,數(shù)據(jù)采集架構(gòu)正隨著業(yè)務(wù)需求不斷演進(jìn):
- 從“數(shù)倉驅(qū)動(dòng)”到“湖倉一體”:早期采集主要面向結(jié)構(gòu)化數(shù)據(jù),支撐離線數(shù)倉。如今,采集對象擴(kuò)展至非結(jié)構(gòu)化/半結(jié)構(gòu)化數(shù)據(jù)(如圖文、音視頻、點(diǎn)擊流),支持直接入湖,形成更靈活的“湖倉一體”分析基礎(chǔ)。
- 實(shí)時(shí)化成為標(biāo)配:為支持精準(zhǔn)推薦、實(shí)時(shí)風(fēng)控、運(yùn)營大盤等場景,流式采集與處理能力從“可選”變?yōu)椤氨剡x”,推動(dòng)架構(gòu)向流批一體的方向發(fā)展。
- 云原生與SaaS化:越來越多的數(shù)據(jù)采集產(chǎn)品以云服務(wù)或SaaS形式提供。它們天然具備彈性伸縮、免運(yùn)維、按需付費(fèi)的優(yōu)勢,用戶通過簡單配置即可快速接入多個(gè)數(shù)據(jù)源,極大地降低了使用門檻和技術(shù)成本。
- 智能化與自動(dòng)化:通過引入AI技術(shù),實(shí)現(xiàn)數(shù)據(jù)源Schema的自動(dòng)發(fā)現(xiàn)與同步、數(shù)據(jù)質(zhì)量異常的智能檢測、采集任務(wù)參數(shù)的自動(dòng)調(diào)優(yōu)等,提升運(yùn)維效率與數(shù)據(jù)可靠性。
- 安全與合規(guī)強(qiáng)化:面對日益嚴(yán)格的數(shù)據(jù)安全法規(guī)(如GDPR、個(gè)保法),架構(gòu)中集成了更強(qiáng)的數(shù)據(jù)脫敏、加密傳輸、訪問審計(jì)和隱私計(jì)算能力,確保數(shù)據(jù)流轉(zhuǎn)全過程合規(guī)。
結(jié)論
大數(shù)據(jù)系統(tǒng)數(shù)據(jù)采集產(chǎn)品的架構(gòu),已從單一的數(shù)據(jù)搬運(yùn)工具,演進(jìn)為集連接、處理、傳輸、管理于一體的智能化數(shù)據(jù)管道。在互聯(lián)網(wǎng)數(shù)據(jù)服務(wù)中,它不僅是數(shù)據(jù)價(jià)值鏈的源頭,更是業(yè)務(wù)敏捷性與數(shù)據(jù)驅(qū)動(dòng)能力的基石。隨著邊緣計(jì)算、物聯(lián)網(wǎng)的普及和數(shù)據(jù)要素市場化進(jìn)程的深入,數(shù)據(jù)采集架構(gòu)將繼續(xù)向全域、實(shí)時(shí)、智能、安全的方向深化發(fā)展,以支撐更加復(fù)雜和創(chuàng)新的互聯(lián)網(wǎng)應(yīng)用與服務(wù)。